Table of Contents
Introduction by Nicholas P. Garcia
A Brief Timeline of AI Definitions by Eleanor Tursman
- Artificial Intelligence (ft. Mark Dalton)
- AI System (ft. Dr. Christine Custis, Dr. Nathan C. Walker, Dr. Margaret Mitchell, & Dr. Rumman Chowdhury)
- Automated Decision System (ft. Professor Ben Winters, B Cavello, & Professor Rashida Richardson)
- General-Purpose AI (ft. Anna Lenhart, Stan Adams, Dr. Ranjit Singh, & Miranda Bogen)
Closing: When Not to Define AI by Nicholas P. Garcia
Introduction
by Nicholas P. Garcia
Project Goals
Legal definitions are crucial to the drafting of technology legislation and regulation and are highly-referenced and recycled throughout the lawmaking process. They then cascade from laws to enforcement, leading to unintended consequences if definitions are not carefully scoped. Terms relating to emerging technologies like artificial intelligence (AI) are especially difficult to define due to the fast-changing technological frontier and the broad application of these tools.
For this reason, Congress has historically granted power to executive agencies to interpret definitions and update terms in accordance with new information and best practices. This all changed after the 2024 Loper Bright decision which overturned the “Chevron Doctrine” and significantly weakened agency authority. Now, policy leaders have a new responsibility thrust upon them to get these highly consequential definitions right in legislative text—since they can no longer confer this responsibility to executive agencies—and they urgently need support.
Aspen Digital brought together legal scholars, policy advocates, and leading thinkers in technology to craft a collection of influential definitions of AI, with legal and technological rationales for why a policymaker should choose one potential definition over another in context.
This resource is for policymakers, legislative staff, regulators, advocates, and legal practitioners who need to work with AI definitions as operative legal tools rather than technical descriptions. It assumes there is no single “correct” definition of AI. Instead, it treats definitions as context-dependent choices that can have outsized impact on scope, enforcement, institutional authority, and other downstream legal consequences.
This handbook offers an accessible, easy to use entry point for grappling with the question of how to define AI in a legal context. It is intended to be practical, comparative, and usable by readers who are actively engaging with legislative or regulatory text, whether they are drafting new provisions, interpreting existing ones, or trying to understand how a proposed definition will operate once it leaves the page.
This handbook does not attempt to catalogue every definition of artificial intelligence that exists in statute, regulation, or policy guidance. That would be neither feasible nor especially illuminating. Instead, it offers structured, independent expert analysis of the most influential definitions using a comparative approach. Each entry is intentionally scoped to highlight how a definition works, what it captures or excludes, and what tradeoffs it embeds.
The goal is not depth for its own sake, but clarity: to help readers see how small changes in language—sometimes only a few words—can substantially alter legal interpretation, regulatory reach, and institutional responsibility.
Reading Guide
This handbook is not meant to be read straight through. It is meant to be a starting point for getting an overview of the field, a point of reference for understanding existing definitions and their impacts, and a resource to return to as drafts evolve or one encounters new and unfamiliar definitions. Think of it as a menu of options or, better yet, a branching tree that shows where definitions come from and how they are related.
Each definition entry can be read on its own, but the handbook is most effective when entries are read in relation to one another. Readers working on a specific bill or regulation may wish to start by reading each of the progenitor definitions to get a sense of the options, or by jumping to the entries for the lineage that most closely resembles their draft text and reading the variations and comparisons through.
Finally, while the handbook does not aim to be exhaustive, it aims to be clarifying. If it succeeds, readers should come away not with a single preferred definition of AI, but with a clearer understanding of the consequences of choosing one over another in a given context.
How things are organized
To make comparisons more explicit, definitions in this handbook are clustered by lineage. A lineage refers to a family of definitions that trace back to a common progenitor and then branch, mutate, or are repurposed across jurisdictions and use cases.
Where AI is defined in existing or proposed law today, it almost invariably adopts or uses a variant from one of these four lineages:
- Artificial Intelligence from the NDAA, rooted in early US defense and national security contexts and the one most often adopted without change directly through reference.
- Artificial Intelligence System from the OECD, which emphasizes capability, autonomy, and international harmonization.
- Automated Decision System from the Algorithmic Accountability Act, which defines scope through decisionmaking impact rather than technical capability.
- General-Purpose Artificial Intelligence from the EU AI Act and more recent policy, focused on models with broad, downstream applicability.
Readers should resist the temptation to treat these categories as mutually exclusive or as competing “schools.” In practice, definitions routinely borrow from multiple lineages, combining related terms or adopting aspects of language—whether through thoughtful intent or compromise-seeking hybridization. This handbook aims to push more efforts towards thoughtful, intentional engagement with their definition, and a clear picture of the impact of choices and changes.
Why lineage matters
We organized the handbook this way for practical reasons that emerged repeatedly in interviews and background conversations with legislative staff and policy drafters. Across jurisdictions and policy domains, we observed striking repetition in definition language, even where the laws and policies pursued very different goals. Definitions were often reused wholesale, lightly modified, or combined, and there is little visibility into the assumptions carried through from prior contexts or companion terms modifying a definition’s scope that may have been lost along the way.
By tracing definitions back to their progenitors, lineage analysis makes those inheritances visible. It allows readers to see how changing a single phrase (e.g., introducing “implicit objectives,” or shifting from “decisions” to “outputs”) can alter how a law is interpreted, enforced, or challenged. It also surfaces the kinds of questions staffers routinely confront while drafting: what is in scope, who is covered, where discretion lies, and how future technologies will be treated.
How to read each entry
Each entry in this handbook follows a common structure to make comparison easier. Entries begin with brief factual metadata like jurisdiction, date, status, and enforcing entity to situate the definition within its legal and institutional context. At the top is the definition text itself, and where applicable, definitions are presented in direct comparison to a progenitor or closely related predecessor, making lineage relationships and points of divergence clear without needing to reference multiple documents at once.
Most entries also surface related or companion terms that meaningfully shape scope in practice. Terms such as “developer,” “deployer,” “consequential decision,” or “high-risk system” are often as important as the AI definition itself. Readers should understand paired and related terms as external components of the definition; they are often key signals about scope, intent, and interpretation.
Following the definition text, each entry is organized around three analytic sections. The Motivation section explains why the definition was written and what problem, opportunity, or political moment it was responding to. The Approach section provides the core analysis: what the definition includes or excludes, how it operates in context, what tradeoffs it embeds, and how changes from predecessor language affect interpretation or enforcement. The Reception section situates the definition after introduction—where it has been adopted or reused, how it has been received by policymakers, industry, advocates, or courts, and where meaningful critiques have emerged. Each entry concludes with Additional Resources pointing readers to primary sources and deeper analyses for further research.
Together, this structure is meant to allow readers to scan quickly for orientation, read selectively for comparison, or dive deeply into a single definition—while maintaining enough consistency across entries to support side-by-side analysis.
A Brief Timeline of AI Definitions
by Eleanor Tursman
What follows is a history of definitions of AI in legal and legislative contexts principally focused on the US, with a few important international texts that have influenced legislators in the United States.
Although “artificial intelligence” has been referenced in bills going as far back as the 1970s, the first legal definition for AI in Congress was introduced in 2018, in the John S. McCain National Defense Authorization Act for Fiscal Year 2019 (McCain NDAA). Shortly afterwards, the US joined forty-eight countries affiliated with the Organisation for Economic Co-operation and Development (OECD) and the European Union (EU) to adopt a nonbinding legal definition of AI in the Recommendation of the Council on Artificial Intelligence.
These definitions focus on outlining the capabilities that make an AI system officially “AI” in the legal context. NIST’s AI Risk Management Framework and the National Artificial Intelligence Initiative Act of 2020 (NAIIA) build off of this OECD definition, in addition to state bills like California’s Safe and Secure Innovation for Frontier Artificial Intelligence Models Act (SB-1047, vetoed in 2024). While these two definition branches are the oldest, a proliferation of proposed federal AI bills use either one or both of the McCain NDAA and NAIIA AI definitions, and many of the AI-related executive orders across both the Biden and Trump administrations use NAIIA’s AI definition.
Around the same time as the McCain NDAA, a different approach emerged to defining AI through the lens of critical decisions and risk, as opposed to capabilities. In the EU, the AI Act uses the OECD AI definition while introducing tiered layers of risk. At the federal level in the US, the Algorithmic Accountability Act of 2019 (AAA) takes a technology-agnostic approach, capturing AI systems within a broader “automated decision system” definition. The AAA’s approach has spread to the recent rulemaking process for the California Privacy Protection Act and other proposed federal legislation like the (since-stricken) AI regulation moratorium in Trump’s flagship budget bill, the One Big Beautiful Bill Act.
In 2022, the release of ChatGPT and subsequent proliferation of generative AI models like large language models (LLMs) and image generators instigated a push to modify existing capability-focused definitions to ensure they covered these new systems. The OECD updated their definition in 2024, which was then leveraged in a number of state bills in the US like Colorado’s AI Act (SB24-205). For tech-agnostic definitions like the one in AAA, no updates were needed.
Most recently, there has been a push to further define models or combinations of models that have more general-purpose applications than other types of AI systems. Historically, AI systems were narrow in what kinds of information they could take in and output. As these systems are made more complex and “general,” it becomes harder to anticipate all the possible outcomes of using these tools. Like the difference between a calculator and a more general-purpose computer, this expansion in possible outputs makes it more difficult for developers to forecast how different entities will use their systems. From a legislative perspective, general-purpose models complicate regulation and liability because the potential actors influencing an AI system’s performance grow more numerous and complex.
In the EU, this push manifests in the general-purpose AI definition of the AI Act and subsequent guidance on its interpretation, which build off of a legislative approach meant to capture specific major AI companies through mechanisms like training compute thresholds. This approach is similar to how the EU’s Digital Services Act uses a threshold of 45 million users per month to identify covered Very Large Online Platforms and Very Large Online Search Engines. There was cross-pollination between the EU and US under the term “foundation models,” language coined at Stanford in 2021 which has since been adopted in definitions in federal bills, executive orders in the Biden administration, and state bills like California’s Transparency in Frontier Artificial Intelligence Act (SB-53). A related term, “frontier model,” was included in New York’s recently signed Responsible AI Safety and Education Act.
Thank you to Dr. Nathan C. Walker, whose research was invaluable for writing this brief timeline.
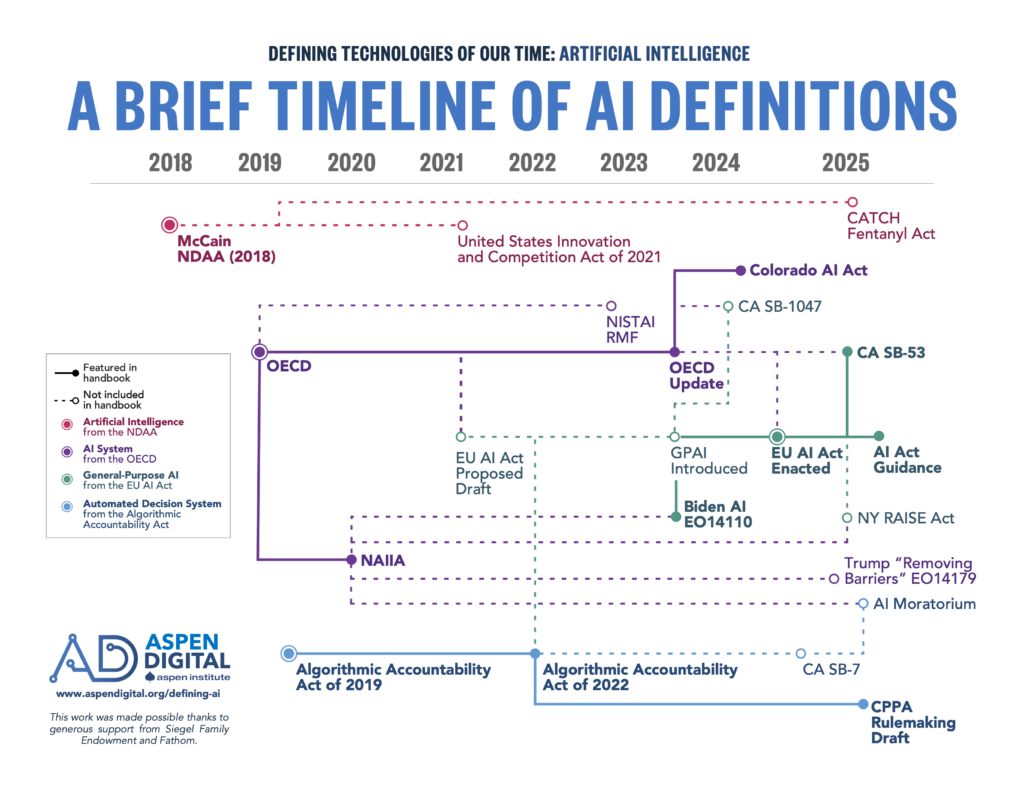
This overview and corresponding chart are our best interpretation at how the current AI definition landscape is intertwined.
Lineages
Closing: When Not to Define AI
by Nicholas P. Garcia
Throughout this handbook, we have taken legal definitions of artificial intelligence seriously, examining how they are written, borrowed, modified, and operationalized across jurisdictions and policy contexts. That focus reflects current reality: lawmakers, regulators, and advocates are repeatedly asked to define AI, and the consequences of those choices are increasingly high-stakes. But there is an important alternative path that deserves consideration: sometimes, the best approach is to avoid needing to define AI at all, even if the starting point for legal action is motivated by AI.
The road not taken in some legislative efforts is to skip defining AI entirely, and to even avoid mentioning AI in statutory text. This should not necessarily be viewed as simply skirting a difficult challenge or the failing to understand the technology. In some cases, it is a deliberate and disciplined choice grounded in a recognition that the objectives of a law do not actually turn on whether a system qualifies as AI, but rather on the risks, harms, or institutional practices that the law seeks to address.
Simply put, if in reading this book you are finding that none of the various definitions are meeting your needs or objectives, consider that when legislating about AI, sometimes you do not need to legislate about AI itself.
The technology-neutral approach
Technology-neutral approaches have a long pedigree in law and regulation. Rather than anchoring obligations to a specific class of tools, they focus on conduct, outcomes, risks, or institutional roles. In the context of emerging technologies, this approach can be especially valuable. AI often renders certain risks more salient, more scalable, or more opaque—but it rarely invents those risks from whole cloth.
Discrimination, unsafe products, deceptive practices, invasions of privacy, environmental harm, labor displacement, and market concentration all predate modern AI systems. In many contexts, the most durable legal interventions target these underlying harms directly, without hinging applicability on whether a particular system meets a contested technical definition.
A technology-neutral framing can also be advantageous when the policy goal is to support innovation, scientific advancement, or technological progress. Fixating on a particular technology of the day risks freezing a moment in time. While an AI bill might capture popular attention, artificially directing inquiry toward or away from specific approaches, rather than allowing for more open-ended experimentation, can undermine the real goal. History is replete with examples of regulatory frameworks that unintentionally privileged certain technical paths simply because those paths were legible to policymakers at the time of drafting.
For example, early US telecommunications law was drafted around a circuit-switched, voice-centric model of communication, which made packet-switched data networks difficult to classify once they emerged. Similarly, early internet copyright law assumed centralized intermediaries capable of monitoring and responding to infringement, embedding notice-and-takedown obligations that mapped cleanly onto large platform-like service providers. This framework implicitly privileged centralized technical architectures over decentralized or peer-to-peer systems, not as a normative choice, but because those architectures were easier for lawmakers to see, assign responsibility to, and regulate.
In this sense, technology neutrality can be a way of preserving flexibility, avoiding premature lock-in, and ensuring that legal obligations track social objectives rather than transient technical categories.
Definitional uncertainty as a signal
One theme that should stand out to readers of this handbook is the persistent difficulty of calibrating AI definitions. Across lineages, jurisdictions, and use cases, drafters struggle with the same core problem: how to draw a boundary that is neither so narrow that it is easily evaded, nor so broad that it sweeps in ordinary software or well-understood forms of automation.
This challenge of inclusion versus exclusion is not a drafting failure so much as a signal. It reflects the reality that “AI” is not a neat or stable category of computing technologies. It is an evolving cluster of techniques, applications, and institutional practices, shaped as much by business models, marketing buzzwords, and cultural practices as by technical properties.
Many of the definitions examined in this handbook attempt to manage this uncertainty through companion terms and scoped obligations. Rather than relying on the AI definition alone, they pair it with concepts like “developer,” “deployer,” “high-risk system,” or “consequential decision.” These auxiliary definitions often do the real work of determining who is covered, when obligations attach, and how enforcement operates in practice.
This design choice is telling. It suggests that even when drafters do define AI, they frequently rely on other concepts to make the law function. In some cases, those concepts may be sufficient on their own!
Change over time—and the limits of foresight
Another lesson that emerges across entries is how tightly definitions are shaped by the moment. Several of the entries describe in their Motivation sections how these definitions arose from the cultural and political response to the rise of “generative AI.” Terms like “content,” “implicit objectives,” or “general-purpose models” reflect attempts to adapt existing frameworks to a sudden and highly visible shift in capabilities and usage patterns for AI.
Many of these definitions aim to be flexible and forward-looking, and in some cases they succeed. But technological change can be dramatic and unpredictable, often in ways that defy the assumptions embedded in statutory text. Definitions that seem capacious today may become inadequate tomorrow—not because they were poorly drafted, but because the underlying technological landscape, business models, or usage moved in an unexpected direction.
This reality should prompt a threshold question for drafters: do the objectives of the proposed law truly depend on capturing AI as such or would a broader, more technologically neutral approach better serve those aims over time? If the answer is the latter, defining AI may introduce unnecessary fragility into the legal framework.
Choosing when to define
None of this is an argument against defining AI categorically. In many contexts definitions are unavoidable, clarifying, and extremely useful. This handbook exists precisely because those moments are frequent and consequential.
But that choice is still a choice. Avoiding an AI definition can be an intentional design decision, one that reflects clarity about policy goals rather than uncertainty about technology or a shortcut out of making a hard call. In some cases, the most effective laws will be those that regulate behavior, responsibility, and harm directly, leaving the taxonomy of tools to evolve outside the statute.
However, in the other cases where grappling with AI and its definition directly is necessary or desirable, this handbook aims to serve. If it succeeds, it should make our choices about how to define AI easier, clearer, and more intentional; it should illuminate the intent, or else the carelessness, of proposed definitions that we encounter; and it should help us thoughtfully and consciously define this technology of our time.
About the Authors
Writers

Stan Adams
Author of analysis of the EU Guidelines on General-purpose AI Models
Read about Stan
Stan Adams is the Wikimedia Foundation’s Lead Public Policy Specialist for North America. He advocates for laws and policies to help projects like Wikipedia thrive and works to protect the Wikimedia model from harmful policies. This work includes defending legal protections, like Section 230, that protect volunteer editors from frivolous lawsuits and advocating for stronger laws to protect the privacy of people who read and edit Wikipedia. Stan has spent nearly a decade working on tech policy issues including digital copyright, free expression, privacy, and AI. Prior to his role at the Wikimedia Foundation, Stan served as a general counsel to a US Senator and as a deputy general counsel at the Center for Democracy and Technology. Stan enjoys reading, listening to music, playing games, and spending time in the woods.

Miranda Bogen
Author of analysis of California Bill SB-53
Read about Miranda
Miranda Bogen is the founding Director of CDT’s AI Governance Lab, where she works to develop and promote adoption of robust, technically-informed solutions for the effective regulation and governance of AI systems.
An AI policy expert and responsible AI practitioner, Miranda has led advocacy and applied work around AI accountability across both industry and civil society. She most recently guided strategy and implementation of responsible AI practices at Meta, including driving large-scale efforts to measure and mitigate bias in AI-powered products and building out company-wide governance practices. Miranda previously worked as senior policy analyst at Upturn, where she conducted foundational research at the intersection of machine learning and civil rights, and served as co-chair of the Fairness, Transparency, and Accountability Working Group at the Partnership on AI.
Miranda has co-authored widely cited research, including empirically demonstrating the potential for discrimination in personalized advertising systems and illuminating the role artificial intelligence plays in the hiring process, and has helped to develop technical contributions including AI benchmarks to measure bias and robustness, privacy-preserving methods to measure racial disparities in AI systems, and reinforcement-learning driven interventions to advance equitable outcomes in products that mediate access to economic opportunity. Miranda’s writing, analysis, and work has been featured in media including the Harvard Business Review, NPR, The Atlantic, Wired, Last Week Tonight, and more.
Miranda holds a master’s degree from The Fletcher School at Tufts University with a focus on international technology policy, and graduated summa cum laude and Phi Beta Kappa from UCLA with degrees in Political Science and Middle Eastern & North African Studies.

Dr. Rumman Chowdhury
Author of analysis of the Colorado AI Act
Read about Rumman
Dr. Rumman Chowdhury (she/her) is a globally recognized leader in data science and responsible AI, uniquely positioned at the intersection of industry, civil society, and government. She is a sought-after speaker at high-profile venues, including TED, the World Economic Forum, the UN AI for Good Summit, and the European Parliament, where she brings a rare combination of technical expertise and real-world implementation experience. She is the former US Science Envoy for AI at the US Department of State; the former Engineer Director of Machine Learning, Ethics and Transparency at Twitter; the founder and CEO of Parity AI (acquired by Twitter); and the former Managing Director of Responsible AI at Accenture. Rumman co-founded Humane Intelligence in 2022 and served as its CEO until August 2025. She stepped down to launch her new startup, details about which are coming soon. Rumman holds dual Bachelor degrees from MIT, a Master degree from Columbia University, and completed her PhD in Political Science at UC San Diego. She remains a Distinguished Advisor of Humane Intelligence, the nonprofit.

Dr. Christine Custis
Author of analysis of the the OECD Recommendation of the Council on Artificial Intelligence
Read about Christine
Dr. Christine Custis is a Research Associate and Program Manager for the Science, Technology, and Social Values Lab. A computer scientist and organizational strategist whose work has spanned industry, civil society, and academia, Dr. Custis has more than two decades of experience in the development and governance of emerging science and technology. At IAS, she collaborates with Alondra Nelson on multidisciplinary research and policy initiatives examining the social implications of AI, genomics, and quantum science.
She previously served as Director of Programs and Research at the Partnership on AI a nonprofit, multisector coalition of organizations committed to the responsible use of artificial intelligence. At PAI, she oversaw the research, analysis, and development of a range of AI-related resources, from policy recommendations and publications to tools, while leading workstreams on labor and political economy; transparency and accountability; AI safety; inclusive research and design, and the public understanding of AI. An expert of both domestic and international policy, Christine served as a member of the Organisation for Economic Co-operation and Development (OECD) expert group on trustworthy AI and previously worked at the MITRE Corporation and IBM. She has advised and collaborated with a range of organizations, including the Global Democracy Coalition, the US National Institute of Standards and Technology, the US National AI Research Resource Task Force, the New America Open Technology Institute, the UC Berkeley Center for Long-Term Cybersecurity, and many others. She holds a M.S. degree in computer science from Howard University and received her Ph.D. from Morgan State University.

Mark Dalton
Author of analysis of the John S. McCain National Defense Authorization Act
Read about Mark
Mark Dalton leads R Street’s technology and cybersecurity policy portfolios as the organization’s senior director of technology and innovation.
Before joining R Street, Mark served as head of strategic planning at the U.S. Naval Undersea Warfare Center (NUWC) Division Newport, where he played a key role in aligning the organization’s acquisition and research initiatives with the strategic needs of the Navy and the Department of Defense. Prior to that, he served as NUWC’s chief engineer for undersea warfare cybersecurity, delivering technical excellence in cyber solutions across research, development, engineering, and testing. He also established NUWC’s inaugural portfolio of cybersecurity research and development, strategically focusing on leveraging artificial intelligence, machine learning, and formal mathematical methods to combat cyber threats.
As a computer scientist, Mark conducted research in the application of reinforcement learning to optimize behaviors in autonomous systems. He also managed numerous installations and tests of prototype technologies aboard U.S. Navy submarines worldwide.
Mark holds a master’s degree in national security and strategic studies from the U.S. Naval War College, a master’s degree in computer science from the New Jersey Institute of Technology, and a bachelor’s degree in information technology from the University of Massachusetts Lowell. He is currently pursuing a PhD in international relations at Salve Regina University.
Mark resides in Portsmouth, Rhode Island, with his wife, Nichole, and their 18-year-old daughter, Addison. His 3-year-old dog, Ziggy, is his loyal officemate.

Anna Lenhart
Author of analysis of the EU AI Act
Read about Anna
Anna Lenhart is a Policy Fellow at Institute for Data Democracy and Politics (IDDP) at George Washington University and a researcher at the University of Maryland Ethics and Values in Design Lab. Her research focuses on public engagement in tech policy and the intersections of privacy, transparency, and competition policy. She most recently served in the House of Representatives as Senior Technology Legislative Aid to Rep Lori Trahan (117th Congress) and as a Congressional Innovation Fellow for the House Judiciary Digital Markets Investigation (116th).
Prior to working for Congress, Anna was a Senior Consultant and the AI Ethics Initiative Lead for IBM’s Federal Government Consulting Division, training data scientists and operationalizing principles of transparency, algorithm bias and privacy rights in AI and Machine Learning systems. She has researched the human right to freedom from discrimination in algorithms, public views on autonomous vehicles and the impact of AI on the workforce. She holds a master’s degree from Ford School at University of Michigan and a BS in Civil Engineering and Engineering Public Policy from Carnegie Mellon University. Prior to graduate school, Anna was the owner of Anani Cloud Solutions, a consulting firm that implemented and optimized Salesforce.com for non-profit organizations.

Dr. Margaret Mitchell
Author of analysis of the OECD Updated Recommendation
Read about Margaret
Dr. Margaret Mitchell is a researcher focused on machine learning (ML) and ethics-informed AI development. She has published over 100 papers on natural language generation, assistive technology, computer vision, and AI ethics, and holds multiple patents in the areas of AI conversation generation and sentiment classification. She has been recognized in TIME’s Most Influential People; Fortune’s Top Innovators; and Lighthouse3’s 100 Brilliant Women in AI Ethics.
She currently works at Hugging Face as a researcher and Chief Ethics Scientist, driving forward work on ML data processing, responsible AI development, and AI ethics. She previously worked at Google AI, where she founded and co-led Google’s Ethical AI group to advance foundational AI ethics research and operationalize AI ethics internally. Before joining Google, she worked as a researcher at Microsoft Research and as a postdoc at Johns Hopkins.
She has spearheaded a number of workshops and initiatives at the intersections of diversity, inclusion, computer science, and ethics. Her work has received awards from Secretary of Defense Ash Carter and the American Foundation for the Blind, and has been implemented by multiple technology companies. She is most known for her work pioneering “Model Cards” for ML model reporting; developing “Seeing AI” to assist blind and low-vision individuals; and developing methods to mitigate unwanted AI biases.
She holds a PhD in Computer Science from the University of Aberdeen and a Master’s in Computational Linguistics from the University of Washington. She likes gardening, dogs, and cats.

Professor Rashida Richardson
Author of analysis of the California Privacy Protection Agency (CPPA) Rulemaking Draft
Read about Rashida
Professor Rashida Richardson is a Distinguished Scholar of Technology and Policy at Worcester Polytechnic Institute. Rashida is an internationally recognized expert in civil rights and artificial intelligence, and a legal practitioner in technology policy issues. Rashida has previously served as an Attorney Advisor to the Chair of the Federal Trade Commission and as a Senior Policy Advisor for Data and Democracy at the White House Office of Science and Technology Policy in the Biden Administration. She has worked on a range of civil rights and technology policy issues at the German Marshall Fund, Rutgers Law School, AI Now Institute, the American Civil Liberties Union of New York (NYCLU), and the Center for HIV Law and Policy. Her work has been featured in the Emmy-Award Winning Documentary, The Social Dilemma, and in major publications like the New York Times, Wired, MIT Technology Review, and NPR (national and local member stations). She received her BA with honors in the College of Social Studies at Wesleyan University and her JD from Northeastern University School of Law.

Dr. Ranjit Singh
Author of analysis of Safe, Secure, & Trustworthy Development & Use of Artificial Intelligence (EO 14110)
Read about Ranjit
Dr. Ranjit Singh is the director of Data & Society’s AI on the Ground program, where he oversees research on the social impacts of algorithmic systems, the governance of AI in practice, and emerging methods for organizing public engagement and accountability. His own work focuses on how people live with and make sense of AI, examining how algorithmic systems and everyday practices shape each other. He also guides research ethics at Data & Society and works to sustain equity in collaborative research practices, both internally and with external partners. His work draws on majority world scholarship, public policy analysis, and ethnographic fieldwork in settings ranging from scientific laboratories and bureaucratic agencies to public services and civic institutions. At Data & Society, he has previously led projects mapping the conceptual vocabulary and stories of living with AI in/from the majority world, framing the place of algorithmic impact assessments in regulating AI, and investigating the keywords that ground ongoing research into the datafied state.He holds a PhD in Science and Technology Studies from Cornell University. His dissertation research focused on Aadhaar, India’s biometrics-based national identification system, advancing public understanding of how identity infrastructures both enable and constrain inclusive development and reshape the nature of Indian citizenship.

Dr. Nathan C. Walker
Author of analysis of the National Artificial Intelligence Initiative Act of 2020 (NAIIA)
Read about Nathan
Dr. Nathan C. Walker is an award-winning First Amendment and human rights educator at Rutgers University, where he teaches AI ethics and law as an Honors College faculty fellow. He is the principal investigator at the AI Ethics Lab, the founding editor of the AI & Human Rights Index, a contributing researcher to the Munich Declaration of AI, Data and Human Rights, and a non-resident research fellow at Stellenbosch University in South Africa. Dr. Walker is a certified AI Ethics Officer and has held visiting research appointments at Harvard and Oxford universities. He has also served as an Expert AI Trainer for OpenAI’s Human Data Team, where he applied his expertise in law and education to frontier AI models. He has authored five books on law, education, and religion, and presented his research at the UN Human Rights Council, the Italian Ministry of Foreign Affairs, and the U.S. Senate. Nate has three learning disabilities and earned his doctorate in First Amendment law and two master’s degrees from Columbia University. An ordained Unitarian Universalist minister, Reverend Nate holds a Master of Divinity from Union Theological Seminary. More at sites.rutgers.edu/walker

Professor Ben Winters
Author of analysis of the Algorithmic Accountability Act of 2019
Read about Ben
Professor Ben Winters is the Director of AI and Privacy at the Consumer Federation of America. Ben leads CFA’s advocacy efforts related to data privacy and automated systems and works with subject matter experts throughout CFA to integrate concerns about privacy and AI in order to better advocate for consumers. Ben is also an adjunct professor at the University of the District of Columbia David A. Clarke School of Law.
Prior to CFA, Ben worked at the Civil Rights Division of the Department of Justice, where he was an Attorney Advisor in the policy section focusing on algorithmic harm in the civil rights context and was Senior Counsel at the Electronic Privacy Information Center (EPIC) where he led the AI/Human Rights project and advocated for accountability through legislative and direct legal action.
Ben is a graduate of Benjamin N Cardozo Law School and the SUNY Oneonta and is a member of the New York State and District of Columbia bars.
Editors

B Cavello
Director of Emerging Technologies at Aspen Digital
Author of analysis of the Algorithmic Accountability Act of 2022
Read about B
B Cavello is a technology and facilitation expert who is passionate about creating social change by empowering everyone to participate in technological and social governance. They serve as director of emerging technologies for Aspen Digital, a program of the Aspen Institute. B also serves as assistant program chair for the Neural Information Processing Systems (NeurIPS) Conference, as a 2025 research fellow with Siegel Family Endowment, and as a board member to Metagov, an interdisciplinary research nonprofit promoting digital self-governance.
Previously, B advised Senator Ron Wyden on issues of privacy, internet governance, and algorithmic accountability. Prior to Congress, they were a research program lead at the Partnership on AI, senior engagement lead for IBM Watson, and director of both product development and community at Exploding Kittens. B has been recognized as an LGBT+ ‘Out Role Model,’ Global Crowdfunding ‘All-Star,’ and was selected as an MIT-Harvard Assembly Fellow for the 2019 Ethics and Governance in Artificial Intelligence Initiative cohort.

Nicholas P. Garcia
Senior Policy Counsel at Public Knowledge
Read about Nicholas
Nicholas P. Garcia is a Senior Policy Counsel at Public Knowledge, focusing on emerging technologies, intellectual property, and closing the digital divide. Before joining Public Knowledge, Nick served as an Assistant District Attorney in the Investigations Division of the Bronx County District Attorney’s Office, where he investigated and prosecuted cybercrime, fraud, grand larceny, and organized crime. He previously worked as a Legal Intern at Public Knowledge and as a Student Attorney for the Communications & Technology Law Clinic at Georgetown University Law Center’s Institute for Public Representation.
Nick received his J.D. from Georgetown University Law Center, his M.A. in Ethics and Society from Fordham University’s Center for Ethics Education, and his B.A. in cursu honorum in Philosophy from Fordham University, where he was a member of the Phi Sigma Tau Honor Society.
Nick is a native New Yorker, and an unabashed nerd who loves video games, science fiction, and tabletop RPGs.

Eleanor Tursman
Emerging Technologies Researcher at Aspen Digital
Read about Eleanor
Eleanor Tursman is an Emerging Technologies Researcher at The Aspen Institute, where they work at the intersection of novel technologies, public education, and public policy. They served as a Siegel Family Endowment Research Fellow from 2022-24.
Eleanor is a computer scientist by training invested in bridging the gap between academic research and policy to promote social good. They believe in advancing science-based governance of artificial intelligence and other emerging technologies, tools which—despite their potential benefits—can also be used to disenfranchise and discriminate against minority groups, threaten democracy, and propagate disinformation.
Prior to joining The Aspen Institute, Eleanor served as a TechCongress fellow in the office of Representative Trahan (D-MA-03), providing technical and scientific support for topics including health technology, educational technology, artificial intelligence, algorithmic bias, and data privacy. They also worked as a computer vision researcher at Brown University, with a specialty in 3D imagery and the human face. Their research centered on finding new ways to approach deepfake detection, with a focus on long-term robustness as fake video becomes harder to visually identify. Eleanor has an M.S. in computer science from Brown University and a B.A. in physics with honors from Grinnell College.
Acknowledgements
This work was made possible thanks to generous support from Fathom and Siegel Family Endowment.
Thank you to Colin Aamot, Leisel Bogan, Shanthi Bolla, Ryan Calo, Keith Chu, Rebecca Crootof, Leila Doty, Ro Encarnación, Kevin Frazier, Marissa Gerchick, Amir Ghavi, James Gimbi, Divya Goel, Garrett Graff, Margot Kaminski, Kevin Li, Julie Lin, Fergus Linley Mota, Morgan Livingston, J. Nathan Matias, Ashley Nagel, Anna Nickelson, Paul Ohm, Jake Parker, Jake Pasner, Andy Reischling, Connor Sandagata, Lacey Strahm, Meghan Stuessy, Elham Tabassi, Michael Weinberg, and David Zhang for their support of this project.
Defining Technologies of our Time: Artificial Intelligence © 2026 by Aspen Digital. This work in full is licensed under CC BY 4.0.
Individual entries are © 2026 their respective authors. The authors retain copyright in their contributions, which are published as part of this volume under CC BY 4.0 pursuant to a license granted to Aspen Digital.